
|
|
| Home Contact us |
|---|
It can also be used to replace text, regex define a search pattern which is used for
find and find and replace in string operations.
If you want to learn Regex with Simple & Practical Examples, I will suggest you to see this simple and to the point Complete Regex Course with step by step approach & exercises. This video course teaches you the Logic and Philosophy of Regular Expressions from scratch to advanced level.
You are going to use an online Regex tool which is available for free and is quite easy to use and very helpful in sorting out how the regex is working. Open your internet browser and type regex101.com or simply write regex101 in google or any other search engine, the results of search will have this site. Simply click it and now you are there, ready to work. The working area will look like this
The first textfield is for writing regular expression and after that there is an area to write the Test string from which you are going to search for a match. For the time being that introduction is good enough. Later, I will tell you more about the regex101 engine and its characteristics.
/regex/
In some regex engines like Python Re module the regex is encapsulated with inverted commas.r"regex"
However in most cases forward slash at start and end are used and this pattern is followed here.
Usually there are one or more modes applied to the regex. The syntax of mode is that after the second forward slash mode is written. like
/regex/ mode
A more practical application is
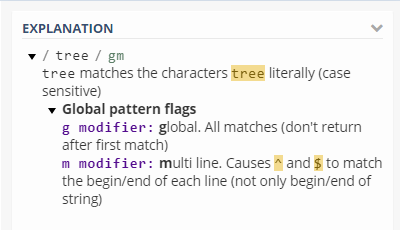
/tree/ gmwhere g is global mode and m is multiline mode and tree is the text to match.

And here is the explanation as shown in regex engine. We will discuss modes later.
The simplest match is a literal character match. Literal means what it appears to be.
a means alphabet a
c means single character c
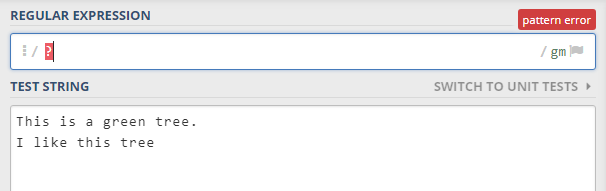
tree means the word treeBut not all characters behave like a or b or tree etc. If you try to match a question mark ? or backslash \ or square bracket [ or plus sign + etc you will not be able to match them literally. Writing these symbols in regex field is going to raise a pattern error like this
These symbols which don't have a literal match are called metacharacters as they have special meaning in regular expressions. Most of them raise a pattern error when used alone. Metacharacter means special characters. These special characters have special meanings in regex and without knowing their specific behavior you can not use them in your regex as it will generate error or will not give the expected results. Like period or dot is metacharacter, but if you use it as a single character in regex with global mode, it will not raise a pattern error but it will match everything, yes literally everything in your test string instead of matching a dot or period, though it will also match the dot or period but it will not leave anything matching all characters in your test string. This is an example of unexpected results.
1. First is standard mode and it means no mode. It has no symbol the syntax is
/regex/
and it will match the first occurence of regex pattern.
2. If you want to match all occurences of a single character or word you may use global mode represented by g. The syntax of global mode is
/ a / g
using g for global mode after the second or closing forward slash results in matching all occurences of a instead of first occurence match.
3. Another important mode is case insensitive mode represented by i. Its syntax is
/ Tree / i
As expected by its name, it results in a match which is case insensitive, i.e. it will match Tree as well as tree
4. Next are single line mode represented by s and multiline mode represented by m. Single line mode treats your string as one line instead of multiple lines and matches for your search pattern. In single line mode dot or period matches all including newline. Its syntax is
/ tree / s
5. While a multiline mode will treat a string consisting of multiline and hence if you want to have matches at individual lines you may use multiline mode. A multiline mode anchors regex with ^ and $. Its syntax is
/ tree / m
At
this point, I should tell another group of metacharacters which are
called complex metacharacters or metacharacters of more than one
character. Its kind of funny that these metacharacters are
metacharacters when we use backslash before them. Some of the examples
are \d \w
\s
\D \W
\S
Now
these are metacharacters with special meanings like \d is used to match
digits from 0 to 9. Now if we drop backslash before these
metacharacters, they become literal characters. Like \d is a
metacharacter dropping backslash it will be d a literal
character.
As discussed above \d is used to match numbers 0 to 9. \D is used to
match anything but numbers 0 to 9.
\w matches word characters which include a to z upper and lower case, 0 to 9 and underscore.
\W matches anything but \w
\s matches whitespace like space, tab etc.
\S matches all but \s
First see how dot or period works in regex.
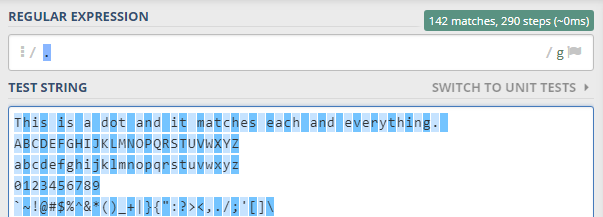
As you can see dot matches all characters, therefore it may be called as wildcard character as it matches all.
Dot is the most commonly used metacharacter in regular expressions and it is also the most commonly misused metacharacter. Dot matches a single character at one time and if standard mode is used it will match only one character without looking what that character is as dot will match the first occurence from left to right and it will match the first character whatever it is.
In global mode, it is going to match every character leaving line break. Yes, dot does not match line break by default. It is the only thing it does not match. If you want dot or period to match line breaks change mode to single line or s. In this mode dot is going to match line break also. Javascript and vbscript do not have this facility of dot matching all. However, in most of regex flavors line break can also be matched with dot in single line mode.
There are certain characters which are non printable. Like tab, new line or line break, carriage return etc. For matching these non printable characters, you have to specify in regex about these characters.
For matching a tab usually \t metacharacter is used.
\f is used to match form feed
\n is for new line character
\r is for carriage return
\v is used in many flavors for a vertical tab.
\a is used for bell
\e is to escape.
Moreover, unicode can also be used for non printable characters. In case the regex engine you are using supports unicode you may use \uFFFF for a unicode character. If your engine doesn't support unicode, you may use \xFF to match a specific character by using its base sixteen hexadecimal index in the character set. Every character which is non printable can be matched in regex or in or part of a set.
With the help of a character class or character set you may direct regex to match only one character out of two or more characters. The syntax of character class is to put two or more characters inside square brackets
[class]
You may put any number of characters in a character class however your regex engine is going to match only one out of a given set of characters.
Like you want to match affect and effect
/ [ae]ffect / g
The regex will match both affect as well as effect.
Similarly words with two different acceptable spellings can be matched by this
if you want to match gray or grey
/ gr[ae]y / g
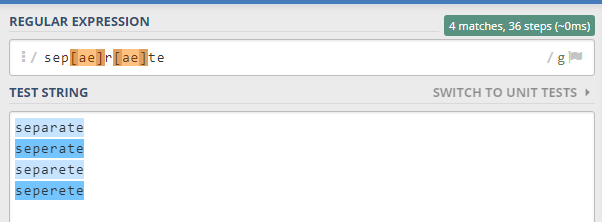
Some words are misspelled for example the word separate four possible forms are
separate
seperete
separete
seperate
to match any variant of separate the regex should be
/ sep[ae]r[ae]te / g
Character ranges:
Instead of writing a large number of characters in a character class you may define ranges. Like instead of writing
[abcdefghij]ar
you can simply write
[a-j]ar
and instead of writing
[ABCDEFGHIJKLMNOPQRSTUVWXYZ] you may use [A-Z] similarly with lower case letters from a to z you may use the character class [a-z].
For numbers you may use [0-9] instead of [0123456789]
Writing a series makes work a bit easy and code a bit tidy and enhances clarity.
Negated Character Class:
After character class series you may use negated character class. A negated character class means don't match any character given in the set, or in other words match any character that is not in the character class.
The syntax of a negated character class is like
[^class]
using a caret just after the opening square bracket and then writing the character class.
[^abc]ip
will not match aip bip cip but it will match any character followed by ip
hence dip eip fip gip etc etc all will be matches
a[^b] does not mean a not followed by b, it means a followed by a character that is not b.
Metacharacters inside a character class:
Metacharacters have special meaning in regex and most raise a pattern error if used alone. In a character class there are certain metacharacters ] \ ^ - these four are metacharacters inside a character class with some special meanings, all other metacharacters are literal characters inside a character class.
Quantifiers are used for repetition. If you want to repeat a certain character there are quantifiers available. For in detail topic of quantifiers and repetition please see detailed topic.
If you want to match flavor and flavour you may use
/ flavou?r /
? as a metacharacter here means zero or 1 repetition. It simply looks either that particular character is present or not. It makes the character as optional, the regex will select if the character is there, and it will also match if the character is not in the test string.
For zero or more repetition * is used. This metacharacter will match in case a character has no existence to any number of occurence.
.* is going to select any number of characters.
For one or more repetition + is used. + metacharacter will match only if the character or group before + occurs atleast once, however it will match any additional occurences.
\d+ will match one digit up to any digit number. \d is the shorthand character class for 0-9 and + means one or more repetition. \d+ is going to match all numbers in the text string.
Another form of repetition is used with braces. There are three cases.
1. {fixed}
2. {min,max}
3. {min,}
The first case with fixed number of repetition. In this scenario use braces and with in braces write in digits the total number of repetitions required to match. For example if you want to match all four digit numbers simply write
/ \d{4} /
This regex will match 1234 4567 2589 5478
but it will not match 12 258 357 8 etc
In the second case if you want to match numbers with minimum of two digits and maximum of five digits then the regex will be
/ \d{2,5} /
This regex will match all numbers which are two digit, three digit, four digit and five digit and it will not match one digit or six digit numbers.
The last case is when you have minimum number of digits required in a number but you don't have information about the maximum number of digits. In that case {min,} is used.
This is a brief overview of repetition.
If you want to match a position instead of any character, use anchors. Some of the commonly used anchors are \b ^ and $. ^ matches the start of a string while $ matches the end of a string. If you have multiple lines then you may opt for multiline mode i.e m after the second forward slash. / regex / m
Some of the examples
/ ^regex$ / mg
/ ^\d{4}$ / mg
If you want to match a word bounday, use \b. A word boundary is a character other than \w. \w is [a-zA-Z0-9_] now either one or more occurence of word character in a series will be matched until a non word character comes which is usually a space and that will be the boundary. \B matches every position where \b does not match. The word boundary is not always a space it can be any other character not included in \w shorthand character class.
To match with word boundary
/ \bregex\b /mg
Alternation is used for or operation. It results in selection one option out of a number of available options. These options are seperated by | the pipe symbol. Any number of options can be written with in the alternation group. However an alternation group should contain atleast two options otherwise there is no used of alternation.
/ I\slike\s(java|python) /g
It will match two strings
I like java
I like python
if I like is a complete match then after that if it is java or python in both cases it will be a match.
some other examples can be
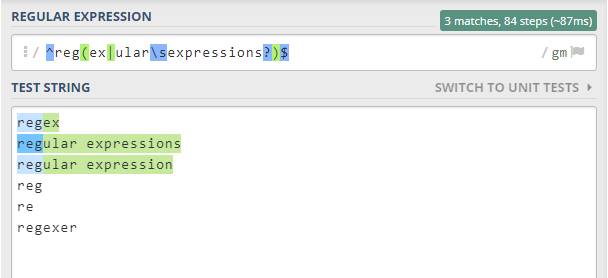
/ (regex|regular expression|regular expressions) / g
/ (car|truck|bus|airplane|rocket) / g
The first expression will match either regex or regular expression or regular expressions while second example will match any word out of car truck bus airplane rocket.
Groups help in applying different operations on a collection instead of a single character. Groups are created by putting parenthesis around a collection of tokens or symbols and later you may apply conditions on these groups. For example you may apply a quantifier to a whole group like + or * or even ?
The whole match is referred to as group 0, if you create a single group it is called group 1. In case of more than one group in regex the regex engine names them as 1,2,3 starting from left to right.
/ ^(\d{3}) - (\d{2}) - (\d{5})$ / g
Here,
group 0 (\d{3}) - (\d{2}) - (\d{5})
group 1 (\d{3})
group 2 (\d{2})
group 3 (\d{5})
If you have to repeat a group instead of writing the regex for that simply write group number and a backslash before it.
/ ^(\d{3}) - (\d{2}) - (\d{5}) \2 \1$ / g
This is also known as backreferencing. Backreferencing is quite helpful in many situations, it also makes your regex look less clumsy and enhances clarity.
If you don't want to capture any group simply place ?: at the start of group regex engine will not number that group i.e. it will not capture that group and it is a non capturing group. An example is like
(?:non-captured group)
There are certain instances when a certain word before or after match is required. This is called lookaround assertions. They are extremely helpful. Lookaround is of two types lookahead and lookbehind. Lookahead can be positive or negative. Similarly lookbehind can also be positive or negative. Lookaround is technically a group. The regex inside the parenthesis is matched as usuall, however after matching the regex engine looks if a certain word follows it or precedes it or follows and precedes it. In case of a positive reply the match is declared as successful.
First the syntax:
Positive lookahead ?=
Negative lookahead ?!
Positive lookbehind ?<=
Negative lookbehind ?<!
Positive lookahead is to check the presence of an element or character after the given character or group.
a(?=b) will match a in abc but will not match a in acb or bac
Negative look ahead is to see if a certain element does not follow the match
y(?!z) will match y in xyz but will not match y in zyx
Similarly for Positive and negative lookbehind
(?<=y)z will match z in xyz but will not match z in zyx
(?<!y)z will match z in yxz but will not match z in xyz